ITU led project will make automated translation more reliable
According to associate professor at the IT University, Leon Derczynski, the Danish Gigaword Project has the potential to improve everything from automated translation to misinformation detection.
Leon DerczynskiComputer Science DepartmentResearchalgorithmsdata science
Written 2 June, 2021 10:32 by Theis Duelund Jensen
In today’s world we conduct a lot of text and language processing with computers but compared to humans, computers need much more data to understand language. Here is a good example of the problem and the reason why you should never rely solely on Google Translate:
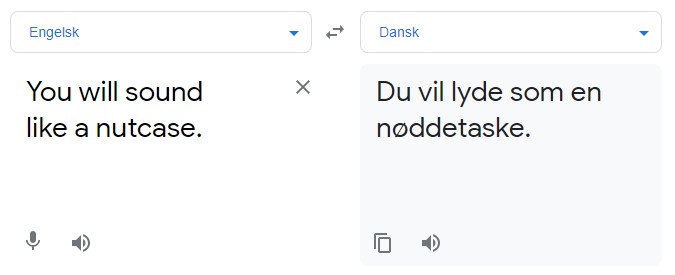
Instead of sounding like a nutcase, you will sound like a “nøddetaske” (literally, “nut purse,” which is not a word in Danish) instead of one of many appropriate Danish translations of the term, such as “galning” or “tosse.” There is a good explanation, though. Google Translate is working with a model – an algorithm trained on data to replicate a specific decision process, for instance, deciding on the proper translation of a sentence – whose Danish language data set is very limited. This is where the IT University-led Danish Gigaword Project comes into play.
The research project, led by associate professor at ITU, Leon Derczynski, and Manuel R. Ciosici, a research scientist at the University of Southern California Information Sciences Institute and visiting scholar at ITU, has compiled the first gigaword dataset with over a billion Danish words, which has the potential to make a service like Google’s much more accurate when translating Danish.
- For a language like English, there was a billion-word data set some thirty years ago. Even the 360,000 speakers of Icelandic have a gigaword project. Danish lacks behind and the gap is widening. It is important, because if you want to do any kind of language understanding for Danish, you need a large dataset to make proper tools, says Leon Derczynski.
And that is exactly the goal of the Danish Gigaword Project. In terms of Natural Language Processing, it takes Danish from a so-called low-resource language to a high-resource language, which ultimately means, we will see better machine translation quality, better speech recognition, and better search results with search engines once the dataset is in use.
Diverse input
But what exactly is a gigaword corpus? In short, it is a vast set of data on the Danish language as it appears in written sources. But to build a dataset that reflects all the nuances and complexities of written communication in a particular language, you need more than just a lot of data; you need a lot of data from a lot of different sources.
- If you train computers only on news text than they can only understand news text, but in our day-to-day life we do not really communicate like, for instance, DR or Weekendavisen. We use text in much more varied ways. I wanted to get as many different types of digital Danish as I possibly could, says Leon Derczynski, who started the project in 2019 and has since led a group of volunteers from all corners of the Danish tech and research spheres.
The paper Leon Derczynski and his co-authors have written on the Danish Gigaword project (“DAGW”), which they are presenting today at the Nordic Conference on Computational Linguistics, details the many sources from which data has been gathered, among them everything from the Danish Parliament’s records of meetings and speeches and a research project on spontaneous speech to Danish Wikipedia pages and a digitized version of the Bible.
Copyright challenges
However, compiling a billion-word dataset comes with a set of unique challenges when you are working in a Danish context. For one thing, licensing is much more restrictive in Denmark compared to for instance in the USA.
- One of the big barriers to our work in Denmark is that people are very cautious about sharing data. In the USA, The New York Times, Associated Press, Xinhua News Agency, and Agence France-Presse donated a combined billion words’ worth of articles to become a public English corpus. Licensing is a significant issue in Denmark, so it has been harder to build this dataset and make it available – which is the core goal. It must be available to researchers as well as to companies, so they can develop new technologies, says Leon Derczynski.
Although copyright laws in Denmark are reasonable, they do present significant challenges to researchers, according to Leon Derczynski. However, he is in positive dialogue with major news outlets about data donations and TV2 Regionerne has already supplied DAGW with approximately 50,000 news articles published between 2010 and 2019.
Better data, better tools
Language technology is not always visible, but it is applied in almost every conceivable context, which is why a vast language corpus is necessary to develop good tools. The Danish billion-word corpus does not only have the potential to improve translation services like Google’s or pave the way for automated grammar correction services like the ones that exist for English; it can help us improve online discourse:
- A lot of my other research is about misinformation detection, online bullying, and harassment. This is hard to detect in a Danish context, because the models for Danish do not have adequate data. But now we have much more detailed information about Danish. This means we can have better misinformation detection and ultimately a better online discourse, says Leon Derczynski.
Ultimately, the DAGW is all about providing researchers and developers with more data to work from. As such, the billion-word corpus’ possibilities are endless and that is exactly what motivated Leon Derczynski to start the project in the first place:
- The big language models which occasionally make the news in relation to artificial intelligence only speak English; that sucks if the language you work in is Danish. Now that we have Danish Gigaword, we can train much more advanced models than before, and start to catch up.
More information:
Follow updates about the Danish Gigaword Project at gigaword.dk
Theis Duelund Jensen, Press Officer, Tel: +45 2555 0447, email: thej@itu.dk